From Cascades to Consensus: A Quarter-Century of Object Detection Evolution (2001–2026)
Exploring the architectural metamorphosis of object detection—from the rigid rule-based scanners of the early 2000s to the fluid, reasoning-driven consensus systems of today.
The capability to identify and localize objects within a visual scene—object detection—stands as one of the definitive challenges in the history of computer vision. Unlike simple image classification, object detection must answer the compound question: "What is where, and how many are there?"
This requirement forces architectures to grapple with the fundamental tension between invariance (recognizing an object regardless of scale or rotation) and equivariance (precisely localizing its position). Over the last 25 years, we have witnessed a profound shift from human-guided heuristics to autonomous reasoning engines.
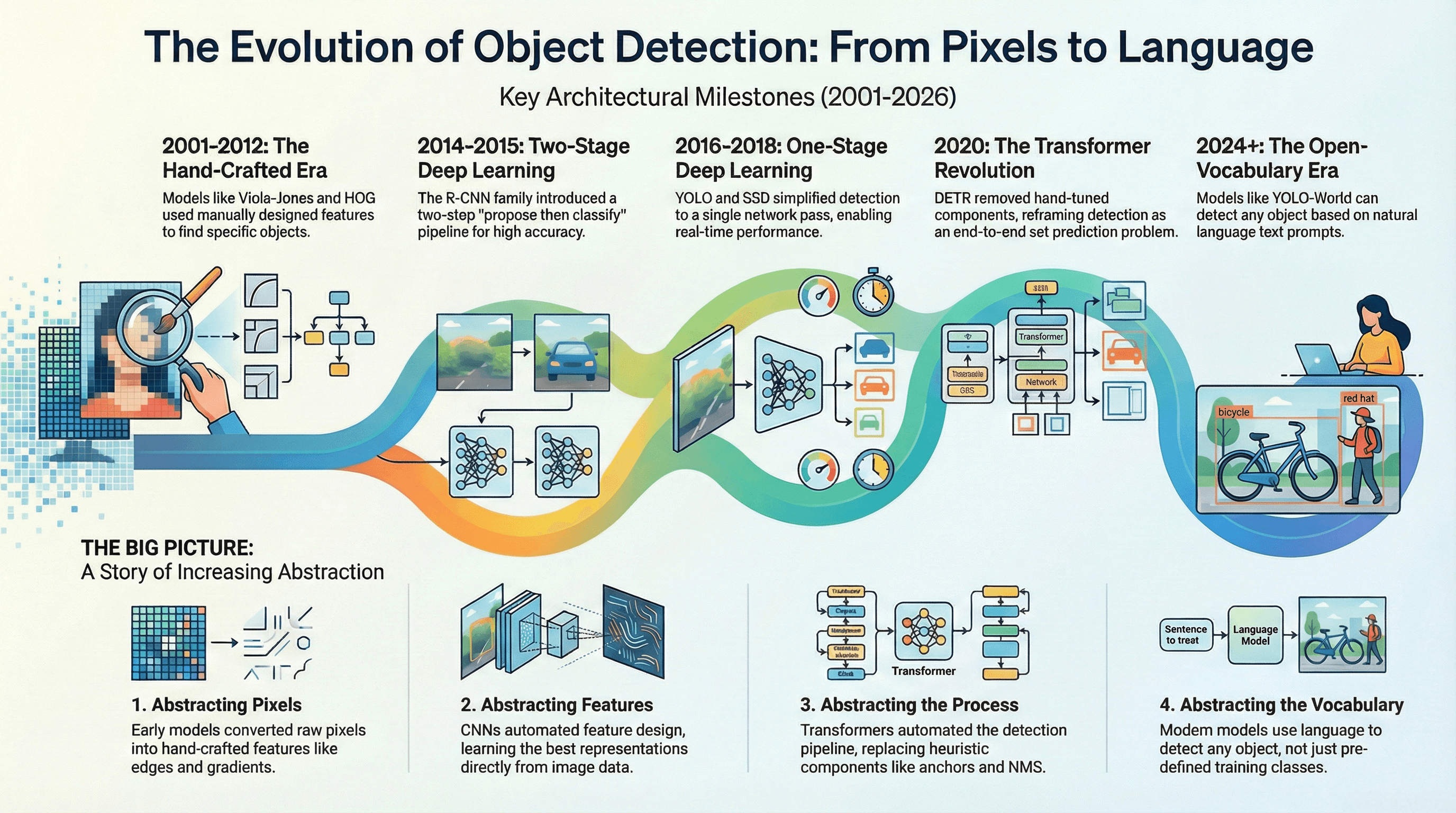
1. The Era of Hand-Crafted Heuristics (2001–2012)
Before deep learning, detection was a problem of "feature engineering." Researchers believed the essence of an object—the curve of a face or the silhouette of a pedestrian—could be mathematically codified into static descriptors.
- Viola-Jones (2001): The first real-time face detector. It introduced Haar-like features (rectangular contrast sensors) and the Integral Image representation, which allows the sum of pixels in any rectangular area to be calculated in constant time using just four array references. It utilized AdaBoost for both feature selection and classification, and an Attentional Cascade architecture to reject background regions early in the pipeline.
- HOG (2005): Histograms of Oriented Gradients moved toward dense feature extraction. It computes local intensity gradients, votes them into orientation bins (typically 9 bins), and applies Block Normalization (L2-norm) to account for illumination changes. These normalized descriptors are then fed into a Linear SVM.
- DPM (2008–2010): The Deformable Part Model used a Star-Structured Architecture consisting of a coarse root filter and higher-resolution part filters. It accounts for object articulation by applying a Deformation Cost (a quadratic penalty of displacement) and was trained using Latent SVM to discover optimal part locations without explicit annotations.
2. The CNN Revolution: Two-Stage vs. One-Stage (2014–2020)
The resurgence of Convolutional Neural Networks (CNNs) shifted the burden of feature design from the engineer to the optimization algorithm.
- The Two-Stage School (R-CNN Family):
- R-CNN (2014): Used Selective Search for region proposals, warped them to fixed sizes, and extracted features via a CNN for classification by Linear SVMs.
- Fast R-CNN (2015): Introduced RoI (Region of Interest) Pooling, which allowed feature extraction directly from the shared convolutional feature map, eliminating redundant computation.
- Faster R-CNN (2015): Replaced Selective Search with the Region Proposal Network (RPN), enabling the first truly end-to-end trainable detection system.
- The One-Stage School (YOLO & SSD):
- YOLO (2016): Framed detection as a single regression problem over a grid, predicting bounding boxes and class probabilities directly from full images in one pass.
- SSD (2016): Utilized Multi-Scale Feature Maps to detect objects of different sizes and Hard Negative Mining (3:1 background-to-object ratio) to stabilize training.
- RetinaNet (2017): Solved the class imbalance problem of one-stage detectors using Focal Loss: . By down-weighting the loss from "easy" background examples, it allowed the model to focus on the sparse set of hard objects.
3. The Transformer Paradigm Shift (2020–2024)
By 2020, the field reached a plateau. Incremental improvements relied on complex hand-crafted components like Non-Maximum Suppression (NMS) and anchor engineering. The introduction of DETR (DEtection TRansformer) changed everything.
DETR replaced the "grid regression" with "Set Prediction." It utilizes a Transformer encoder-decoder architecture where a fixed set of learned embeddings, called Object Queries, interact with the image features via cross-attention. The model employs a Bipartite Matching Loss (using the Hungarian Algorithm) to assign unique predictions to ground truth objects, effectively performing NMS internally and eliminating the need for post-processing. Later iterations like Deformable DETR (2021) introduced Deformable Attention to solve the slow convergence and high computational cost of global self-attention.
4. Multimodal Open-Vocabulary Consensus (2024–2026)
Today, the definition of object detection is undergoing another metamorphosis. We have moved beyond "closed-set" limitations where models could only detect classes seen during training.
- Open-Vocabulary Detectors:
- YOLO-World (2024): Introduces RepVL-PAN (Re-parameterizable Vision-Language Path Aggregation Network). Its key innovation is re-parameterization, allowing text embeddings to be "baked" into the convolutional weights offline, resulting in zero runtime overhead for linguistic processing.
- Grounding DINO (2024): Merges Transformer detectors with linguistic pre-training, using text features to initialize object queries and performing cross-modality fusion in the "neck" of the network.
- SOTA in 2026 (RF-DETR & YOLOv12):
- RF-DETR (2025): Built on a DINOv2 backbone, it achieves state-of-the-art accuracy (54.7% mAP) with deterministic low latency (4.52ms on T4) by completely removing Non-Maximum Suppression (NMS).
- YOLOv12 (2026): Integrates Area Attention (A²), which restricts the attention field to specific regions to maintain a large receptive field without the quadratic cost of standard self-attention. It also utilizes R-ELAN (Residual Efficient Layer Aggregation Network) for deeper stacks and native FlashAttention support.
- Consensus Systems: The cutting edge now involves multiple AI agents (like GPT-5 and Gemini 3 Pro) collaborating. These systems use Reasoning-Guided Detection, where an LLM analyzes the scene ("Is this a safety violation?") and directs the visual detector to find specific evidence.
Conclusion: Toward Visual Reasoning
The journey from the rigid cascades of Viola-Jones to the fluid, reasoning-based consensus of 2026 represents one of the most profound successes in AI. We are no longer training detectors for specific objects; we are training foundation models to understand the relationship between language and vision.
In the coming years, the distinction between "detection," "segmentation," and "reasoning" will vanish. The detectors of the future won't just draw boxes; they will answer questions, engaging in a fluid dialogue with the physical world.